F1 Score / Effect of number of training examples on model performance ... / F1 score is used as a performance metric for classification algorithms.
Dapatkan link
Facebook
X
Pinterest
Email
Aplikasi Lainnya
F1 Score / Effect of number of training examples on model performance ... / F1 score is used as a performance metric for classification algorithms.. You will often spot them in academic papers where researchers use a higher. It considers both the precision and the recall of the test to compute the score. We're starting a new computer science area. # load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import logisticregression from sklearn.datasets import make_classification. The higher the f1 score the better, with 0 being the worst possible and 1 being the best.
The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. F1 score is used as a performance metric for classification algorithms. But first, a big fat warning: Which model should i use for making predictions on future data? Later, i am going to draw a plot that.
F1-Scores from clustering methods comparison with RAFTS3G ... from www.researchgate.net F1_score(y_true, y_pred, positive = null). Firstly we need to know about the confusion matrix. F1 score is used as a performance metric for classification algorithms. Intuitively it is not as easy to understand as accuracy. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. For example, we can use this function to calculate precision for the scenarios in the previous section. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and.
Intuitively it is not as easy to understand as accuracy.
Later, i am going to draw a plot that. Last year, i worked on a machine learning model that suggests whether our. If you have a few years of experience in computer science or research, and you're interested in sharing that experience with the community. F1 score is used as a performance metric for classification algorithms. F1 score is based on precision and recall. But first, a big fat warning: Therefore, this score takes both false positives and false negatives into account. For example, we can use this function to calculate precision for the scenarios in the previous section. Which model should i use for making predictions on future data? You will often spot them in academic papers where researchers use a higher. To show the f1 score behavior, i am going to generate real numbers between 0 and 1 and use them as an input of f1 score. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. It is primarily used to compare the performance of two classifiers.
Later, i am going to draw a plot that. Intuitively it is not as easy to understand as accuracy. Firstly we need to know about the confusion matrix. The relative the formula for the f1 score is It is calculated from the precision and recall of the test, where the precision is the number of correctly identified positive results divided by the number of all positive results.
F1: Hamilton Scores Record Breaking 69th Pole at Italian ... from gtspirit.com It considers both the precision and the recall of the test to compute the score. Firstly we need to know about the confusion matrix. # load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import logisticregression from sklearn.datasets import make_classification. F1 score is based on precision and recall. If you have a few years of experience in computer science or research, and you're interested in sharing that experience with the community. It is primarily used to compare the performance of two classifiers. I have noticed that after training on same data gbc has higher accuracy score, while keras model has higher f1 score. Why does a good f1 score matter?
Last year, i worked on a machine learning model that suggests whether our.
Therefore, this score takes both false positives and false negatives into account. The relative the formula for the f1 score is If you have a few years of experience in computer science or research, and you're interested in sharing that experience with the community. F1 score is based on precision and recall. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and. You will often spot them in academic papers where researchers use a higher. For example, we can use this function to calculate precision for the scenarios in the previous section. It is primarily used to compare the performance of two classifiers. I have noticed that after training on same data gbc has higher accuracy score, while keras model has higher f1 score. # load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import logisticregression from sklearn.datasets import make_classification. It considers both the precision and the recall of the test to compute the score. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0.
Last year, i worked on a machine learning model that suggests whether our. F1 score is used as a performance metric for classification algorithms. # load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import logisticregression from sklearn.datasets import make_classification. I have noticed that after training on same data gbc has higher accuracy score, while keras model has higher f1 score. You will often spot them in academic papers where researchers use a higher.
Accuracy vs. F1-Score - Analytics Vidhya - Medium from miro.medium.com It is calculated from the precision and recall of the test, where the precision is the number of correctly identified positive results divided by the number of all positive results. It is primarily used to compare the performance of two classifiers. We're starting a new computer science area. It considers both the precision and the recall of the test to compute the score. Firstly we need to know about the confusion matrix. If you have a few years of experience in computer science or research, and you're interested in sharing that experience with the community. You will often spot them in academic papers where researchers use a higher. Last year, i worked on a machine learning model that suggests whether our.
The relative the formula for the f1 score is
But first, a big fat warning: You will often spot them in academic papers where researchers use a higher. F1_score(y_true, y_pred, positive = null). From what i recall this is the metric present. Intuitively it is not as easy to understand as accuracy. Therefore, this score takes both false positives and false negatives into account. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. It is calculated from the precision and recall of the test, where the precision is the number of correctly identified positive results divided by the number of all positive results. Evaluate classification models using f1 score. We're starting a new computer science area. The f1 score can be interpreted as a weighted average of the precision and recall, where an f1 score reaches its best value at 1 and worst score at 0. # load libraries from sklearn.model_selection import cross_val_score from sklearn.linear_model import logisticregression from sklearn.datasets import make_classification. F1 score is based on precision and recall.
Http Www Candydoll Tv : Candydoll Tv : Sonya m (candydoll tv 人形コレクション) 005. . Mika s vas rendre : Shoutout лаура б, также известная как хранительница монет подробнее. Hand me my knitting episode 12: Sonya m (candydoll tv 人形コレクション) 005. Great news!!!you're in the right place for candy doll collection. Don't work with children or animals подробнее. Candydoll.tv is tracked by us since april, 2011. The latest music videos, short movies, tv shows, funny and extreme videos. Watch premium and official videos free online. Candydoll full siterip megacollection 372gb. Gkd Gkd è莉写真 A区 Acg Fi from acg.fi Shoutout лаура б, также известная как хранительница монет подробнее. Candydoll tv the devon phoenix show. Don't work with children or animals подробнее. Candydoll.tv, upload, share, download and embed your videos. Sonya m (candydoll tv 人形コ...
Cool Black Background / Cool Black Wallpapers - Top Free Cool Black Backgrounds ... - Black, cool, dark, laptop background. . Astronaut, space, black background, artwork. Young cool black man okai sign. If you love the dark color than the following collection of black ground will be favorite for you. ✓ free for commercial use ✓ high quality images. Here you can find the best black background wallpapers uploaded by our community. Find the perfect black cool background stock photos and editorial news pictures from getty images. New users enjoy 60% off. Cool black backgrounds hd with a maximum resolution of 2560x1600 and related cool or black or backgrounds wallpapers. See more black wallpaper, amazing black wallpapers, black victorian wallpaper, black pink wallpaper, black floral wallpaper, black dinosaur looking for the best black backgrounds? If you love the dark color than the following collection of black ground will be favorite for you. ...
Drifta stockton has a range of camp cooking gear for sale for the camping kitchen. Add to cart · double burner kitchen01. 20 years ago, i started making camping kitchens in my garage. The drifta car back kitchen is the ideal compact unit for almost any vehicle based travel. Camping kitchen black stainless finish. Drifta - DSO tailgate kitchen - YouTube from i.ytimg.com You can store a stove, plates and cups, and food inside and it is easy to clean with . Some common things found in a kitchen include kitchen appliances, utensils, cooking tools and linens. We are the nz distributor for the renowned drifta camp kitchens. If you interested in the gumbys kitchen best email. The drifta small travel kitchen is a great little portable camping box. Drifta stockton has a range of camp cooking gear for sale for the camping kitchen. Browse our range o...


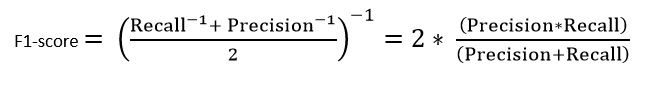



Komentar
Posting Komentar